Participatory Diversity
The participatory Political Diversity (PLD) algorithm creates a recommendation list using political user scores and political article scores. PLD leverages user and article scores derived from interaction data to curate news feeds that reflect a broad spectrum of political views, thus supporting a healthier democratic environment.
For the code, please see the PLD implementation in the repository.
INFO
This tutorial outlines part of the workflow for the Informfully Recommenders repository. The Recommenders Pipeline provides an overview of all components. And you can look at the Tutorial Notebook for hands-on examples of everything outlined here.
Algorithm Overview
PLD is an algorithm that generates a recommendation list by combining political user scores and article scores. The user score can be calculated from a questionnaire survey or based on the user's historical browsing data, as adopted in this project. The article score, on the other hand, is calculated from the user scores of all its readers. In order to assess these scores and apply PLD, the following three questions must be answered:
- How to measure the political scores of users?
- How to assign a political label to a news item?
- How many articles on what political positions should users receive? (I..e, quantify and discretize a normative target distribution across a 1D list or 2D grid.)
The Figure below shows how PLD combined normative target distributions across two 1D lists into a 2D grid for recommendations.
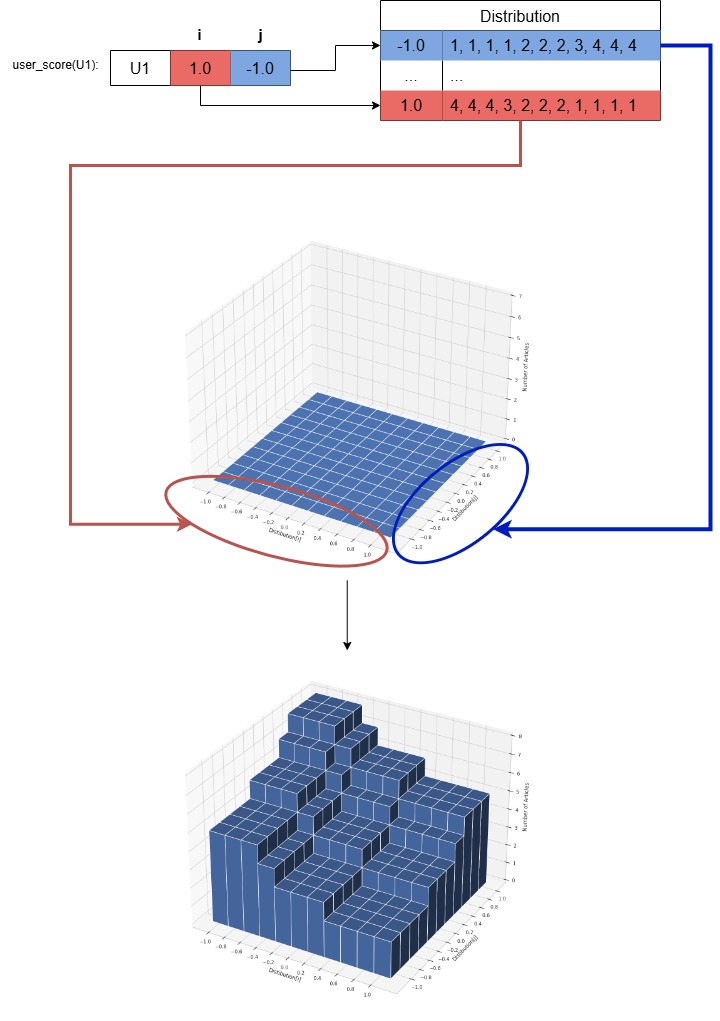
Articles are classified by the frequency of political party mentions, with each article assigned to a single party according to predefined settings. The model can calculate recommendations at the group level, reducing overall runtime as it generates candidate lists. This is possible because the political user score is the only attribute that is considered. This attribute can be defined so that users are assigned to predefined bins. Hence, users in the same bin share the same score and should therefore receive the same recommendations. It is up to researchers to define the distribution (e.g., users can only receive items from nearby bins or from bins on the opposite side of the spectrum).
Open Parameters
Details can be found in the Configuration File.
- name: string, default: 'PLD'. The name of the recommender model.
- trainable: boolean, optional, default: True. When False, the model is not trained, and Cornac assumes it is already pre-trained. (U and V are not 'None').
- verbose: boolean, optional, default: False. When True, running logs are displayed.
- num_users: int, default: 0. The number of users in the dataset.
- num_items: int, default: 0. The number of items in the dataset.
- party_dict: dict. A dictionary whose keys are article IDs and whose values are references to these articles.
- distribution: Nested Lists. Every element in the outer layer is a list that includes the user group type and a list of articles distributed to this user type. An example is the {project_path}/examples/pld_mind.py.
- update_score: boolean, default: True. When 'False', use the existing score files located in the folder './cornac/models/pld'.
- configure_path: str, default: './parameters.ini'. Configure a file that includes parties to be calculated.
Article Classification
PLD is intended primarily for use in an online setting. In a first step, (baseline) users take a survey and are assigned a political score, and read an article. In a second step, each article gets assigned the average political score of its readership. (Both user scores and article scores are mapped into the same political space.) Finally, users in the experimental group receive recommendations based on user-item distance.
When reusing PLD for offline testing requires addressing one critical issue: There are no users available to take the survey. When starting the offline evaluation, users are assigned political scores based on the ratio of political actors' items in their history. To that end, we introduce an offline-only step for annotating political actors/parties in news articles. They are automatically counted across all reading histories. The subsequent logic of PLD remains the same:
- Baseline users read articles.
- New articles get assigned a score on the basis of the average political score of their readership.
- Users in the experimental group receive article recommendations based on the distance between their own political score and the score of the article.
Source
Benefits of Diverse News Recommendations for Democracy: A User Study, Heitz et al., Digital Journalism, 10(10): 1710–1730, 2022.
@article{heitz2022benefits,
title={Benefits of diverse news recommendations for democracy: A user study},
author={Heitz, Lucien and Lischka, Juliane A and Birrer, Alena and Paudel, Bibek and Tolmeijer, Suzanne and Laugwitz, Laura and Bernstein, Abraham},
journal={Digital Journalism},
volume={10},
number={10},
pages={1710--1730},
year={2022},
publisher={Taylor \& Francis}